はじめに
EC2インスタンスを起動する際にvCPUの数を気にすることはよくあることだと思います。
しかしインスタンスファミリーごとに採用されているCPUの種類が異なるため、vCPUの数だけを考慮して採用してしまうと思ったよりもパフォーマンスが発揮できない可能性もあります。
特にコンピューティング最適化インスタンスを使うべきか否かの判断のためには、インスタンファミリーごとに使われているCPUやその性能まで考慮して実行することが望ましいですよね。
本記事では、インスタンスファミリーごとのCPUとそのシングルスレッド性能をまとめてみました。
ぜひ参考にしてみてください。
サイズによる違い
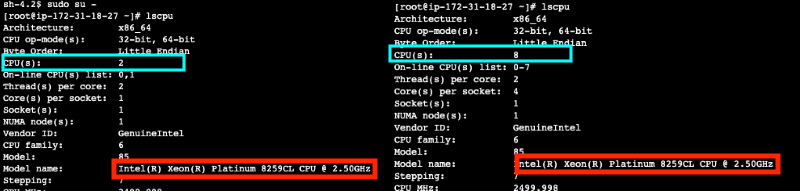
ちなみに前提として、同じインスタンスファミリーであればサイズが異なってもCPUは同じようです。「大きなサイズのインスタンスを立てるとCPUも上位のものになる・・・」なんてことはないので注意したいですね。
ただし、一部のインスタンスファミリーによっては実行されるタイミングによって異なるCPUで実行される場合があるようです。
サイズやAZは関係ないようなので、こちらについては次の表をご確認ください。
Intel製CPU
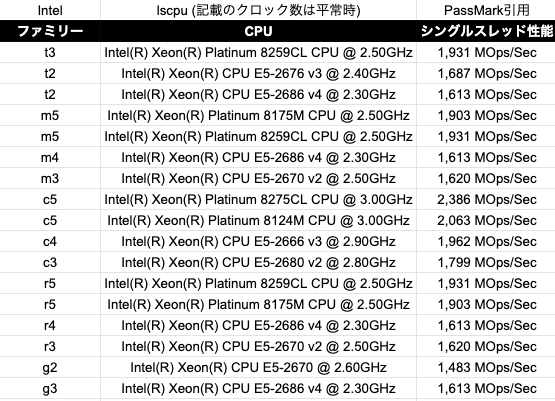
Intel製のCPUを表にまとめました。
シングルスレッド性能はPassMarkからのデータ引用です。
当たり前ですがコンピューティング最適化インスタンスは他のインスタンスタイプよりも性能が高いことがわかります。
1世代古いc4系インスタンスでもm5よりシングルスレッド性能が高いのは意外ですね。
t3系とm5系はどちらも汎用インスタンスなので同じCPUが採用されていますね。
普段はCPU使用率が低い場合はt3系を採用しても良いかもしれません。
ちなみにこの表の中ではg2系インスタンスが最も古い(2013年に公開)ものなのでCPUの世代も古いものになっています。
AMD製CPU
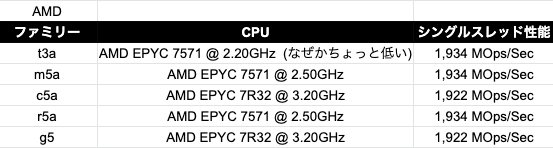
続いてAMD製のCPUですが、なぜかコンピュート最適化インスタンスのシングルスレッド性能が他のファミリーより低く出ています。
この数値はPassMarkからの引用なので実際のEC2での性能関係が本当にこうなっているのかは不明ですが、実際にプログラムを動かすとクロック数の差で性能関係がひっくり返るかもしれませんね。
ということで単純なforループコマンドを複数回実行して実行時間の平均をとってみました。
# 実行コマンド
$ time for i in {1..10000} ; do echo $i; done
————–
◆c5a.large (2vCPU / 4GB)
平均実行時間:0m0.086s
動作クロック:約3300MHz
◆m5a.large (2vCPU / 8GB)
平均実行時間:0m0.121s
動作クロック:約2500MHz
————–
ということで、ちゃんとコンピューティング最適化インスタンスの方が高いパフォーマンスを発揮していそうでした!
ARMアーキテクチャ

ARMアーキテクチャを採用しているGravitonシリーズではインスタンスファミリーに関わらず同じチップセットを採用しているようです。
そのため、汎用インスタンスとコンピューティング最適化で比較してもパフォーマンスの差は見られませんでした。
————–
◆m6g.medium (1vCPU / 8GB)
平均実行時間:0m0.199s
◆c6g.medium (1vCPU / 4GB)
平均実行時間:0m0.200s
※動作クロック数は不明。
————–
ちなみに、まだ東京リージョンではローンチしていないGraviton3ではGraviton2の1.5倍程度の性能があるらしいので同様のコマンドで実行時間を確認してみました。
————–
◆m7g.medium (1vCPU / 8GB)
平均実行時間:0m0.108s
————–
Graviton3では約半分の実行時間になっています。
ARMアーキテクチャは省電力・低パフォーマンスなコアを大量に並列実行させることで強力なパフォーマンスを発揮する思想で採用されていますが、シングルスレッド処理に弱点がありました。しかし次世代では大幅な性能アップが見込めるので幅広いワークロードでの採用が現実的になりますね!
おわりに
今回はEC2インスタンスのCPU事情について調べました。
基本的にはコンピューティング最適化インスタンス以外のインスタンスファミリーではCPU性能に大差がないので、コンピューティング最適化が良いか否かだけ判断すれば良さそうですね。
ただしコア数だけを考慮してx86_64アーキテクチャのCPUからARMアーキテクチャにサーバを移行すると、同じコア数でも大幅に処理性能がダウンしてしまう可能性もあります。なんとなくで良いので、ある程度の性能差について把握しておくと便利かもしれませんね!









コメントを残す