ECSでサービスを展開している方で、ホストインスタンスのスケールインについて悩まされた方は多いのではないでしょうか。
そのうちECSやAutoScalingの機能に追加されるかなと放置していたのですが、2017年にLambdaを使った自動ドレイニング(クリックで開く)の方法が公開されてから、特に音沙汰もありません。
これはもう機能として追加されることはないんでしょうかね・・・。
ということで、せっかくなので公式ブログで紹介されている自動ドレイニングを導入する方法について解説していきます。
とはいえ、ある程度の知識をお持ちの方はブログの内容とCloudFormationを見ればすぐに実装できると思いますが・・・。
ドレイニングの必要性って?
まず前提として、なぜドレイニングを自動化したいのかについて振り返ってみます。
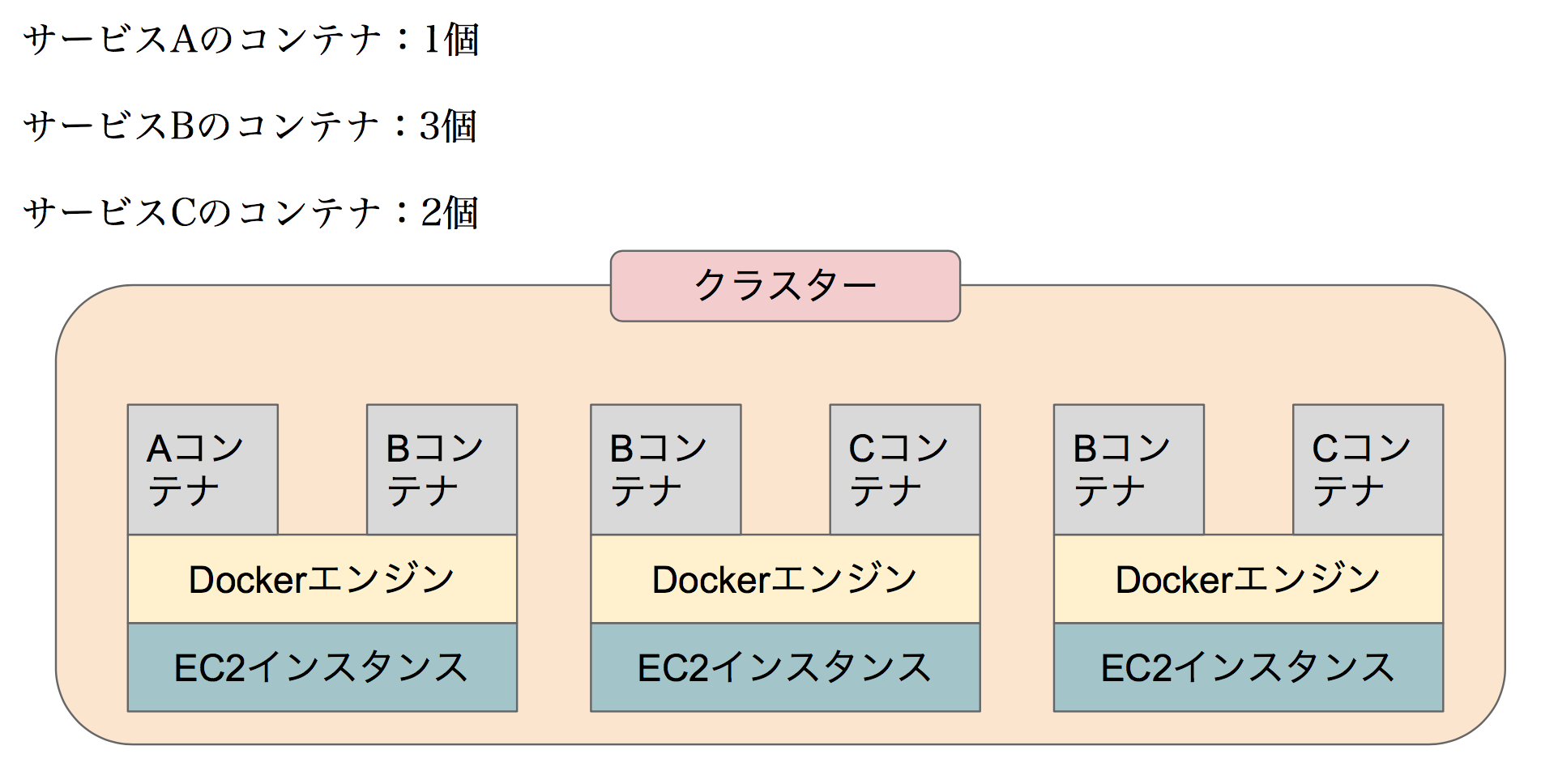
今回の例では、
あるクラスターに3つのホストインスタンスが存在していて、このインスタンスを1台減らしたいという想定でお話しします。
このクラスターにはサービスA/B/Cが設定されており、
・サービスA:コンテナ1個
・サービスB:コンテナ3個
・サービスC:コンテナ2個
が希望値として設定されています。
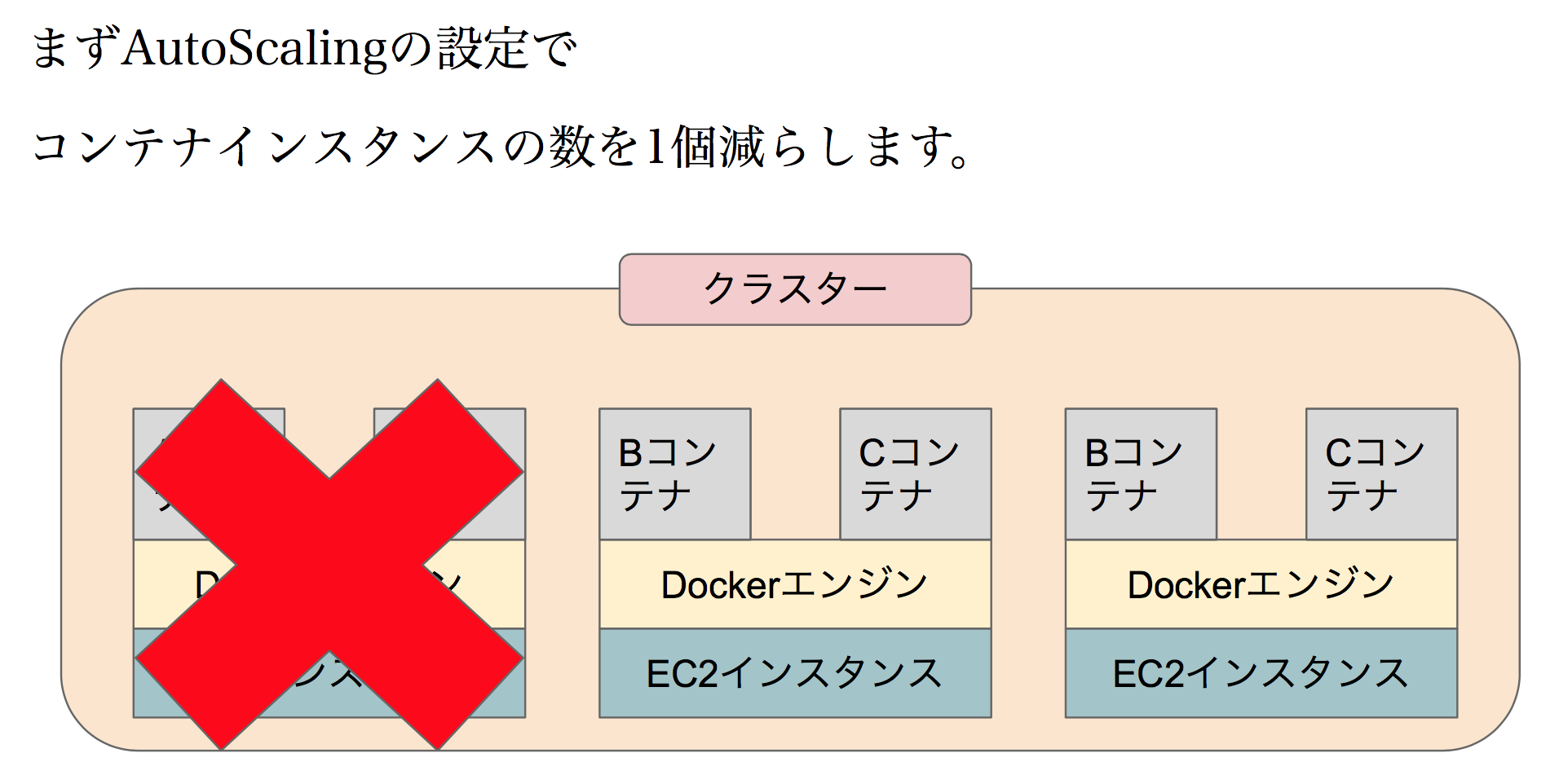
早速ですがAutoScalingで設定しているインスタンスの数を1つ減らしてみましょう。
AUtoScalingは、「古いインスタンスから消す」「AZが均等になるように消す」「コストが高いものから消す」など様々なルールに従ってEC2インスタンスを削除します。
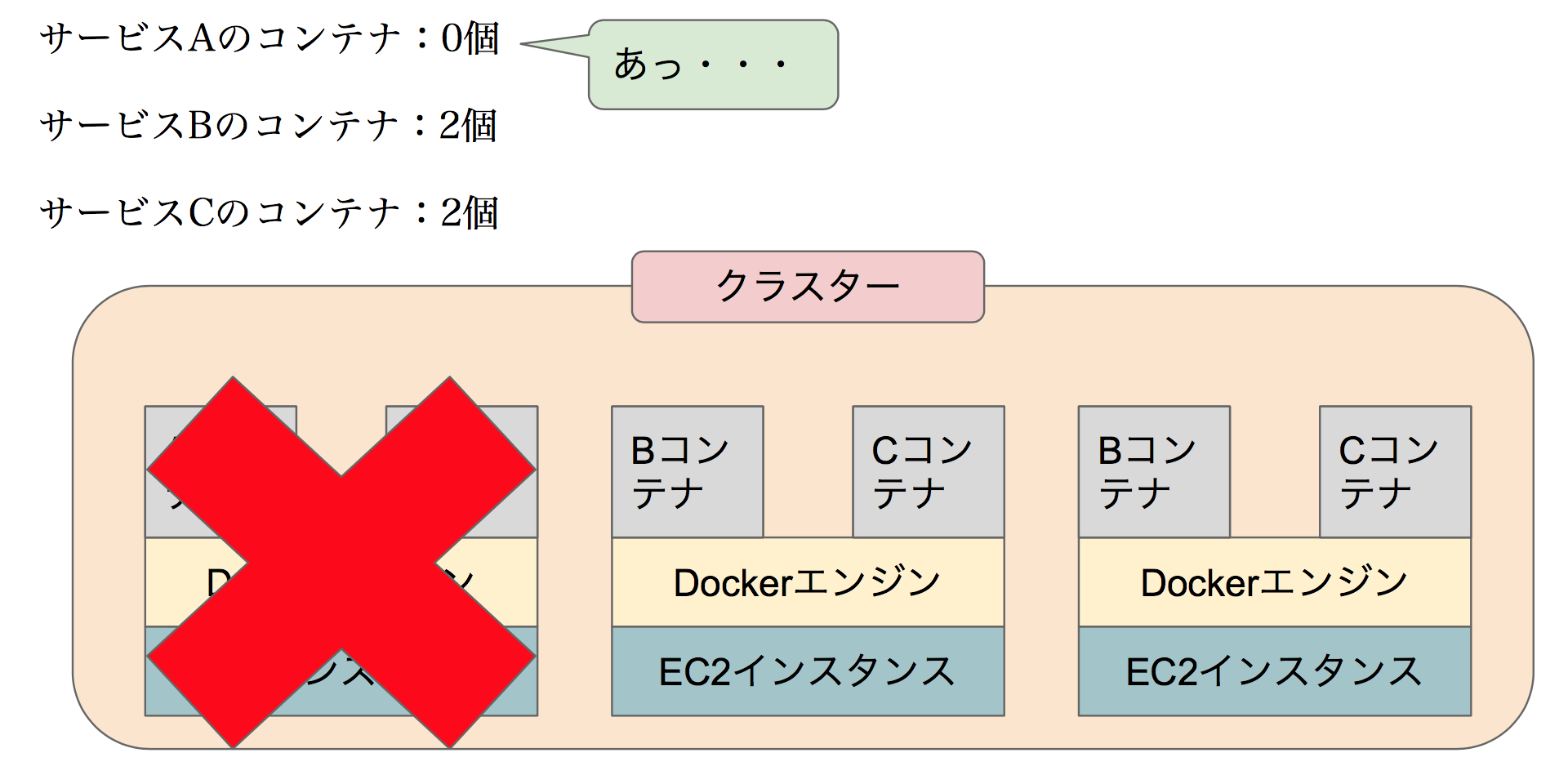
ということで1台のインスタンスが削除されました。
この図を見ればお気づきだとは思いますが、削除直後のサービス毎のコンテナの数は以下の通りです。
・サービスA:コンテナ0個
・サービスB:コンテナ2個
・サービスC:コンテナ2個
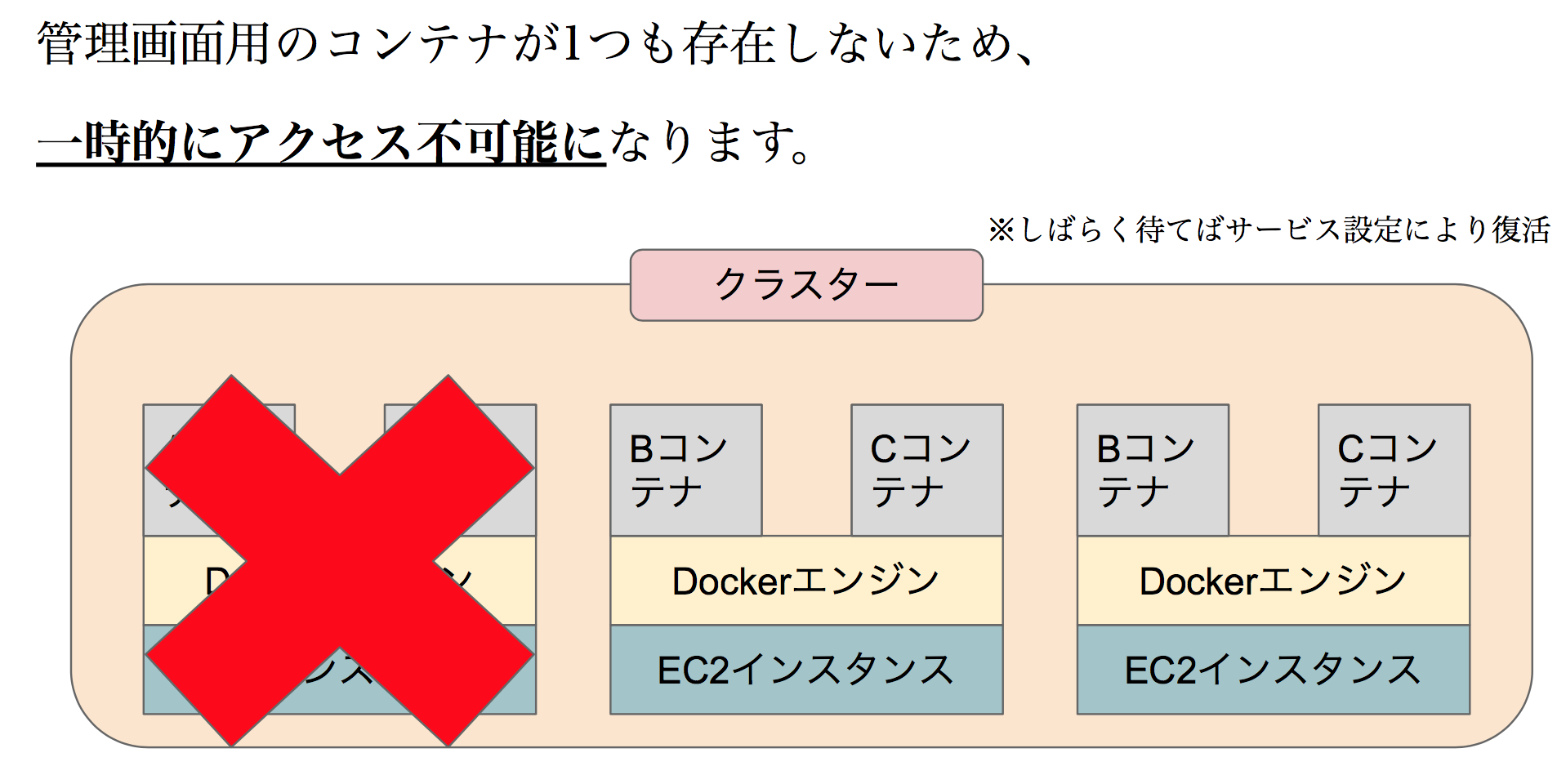
すなわちサービスAについてはダウンタイムが発生してしまいます。
この他にも、ホストインスタンスが停止することによってコンテナも削除されるため、
ある特定のコンテナに接続中のユーザーは突然接続が切られることになります。
ドレイニングにするとこうなる
ではドレイニングとやらを活用したケースを考えてみます。
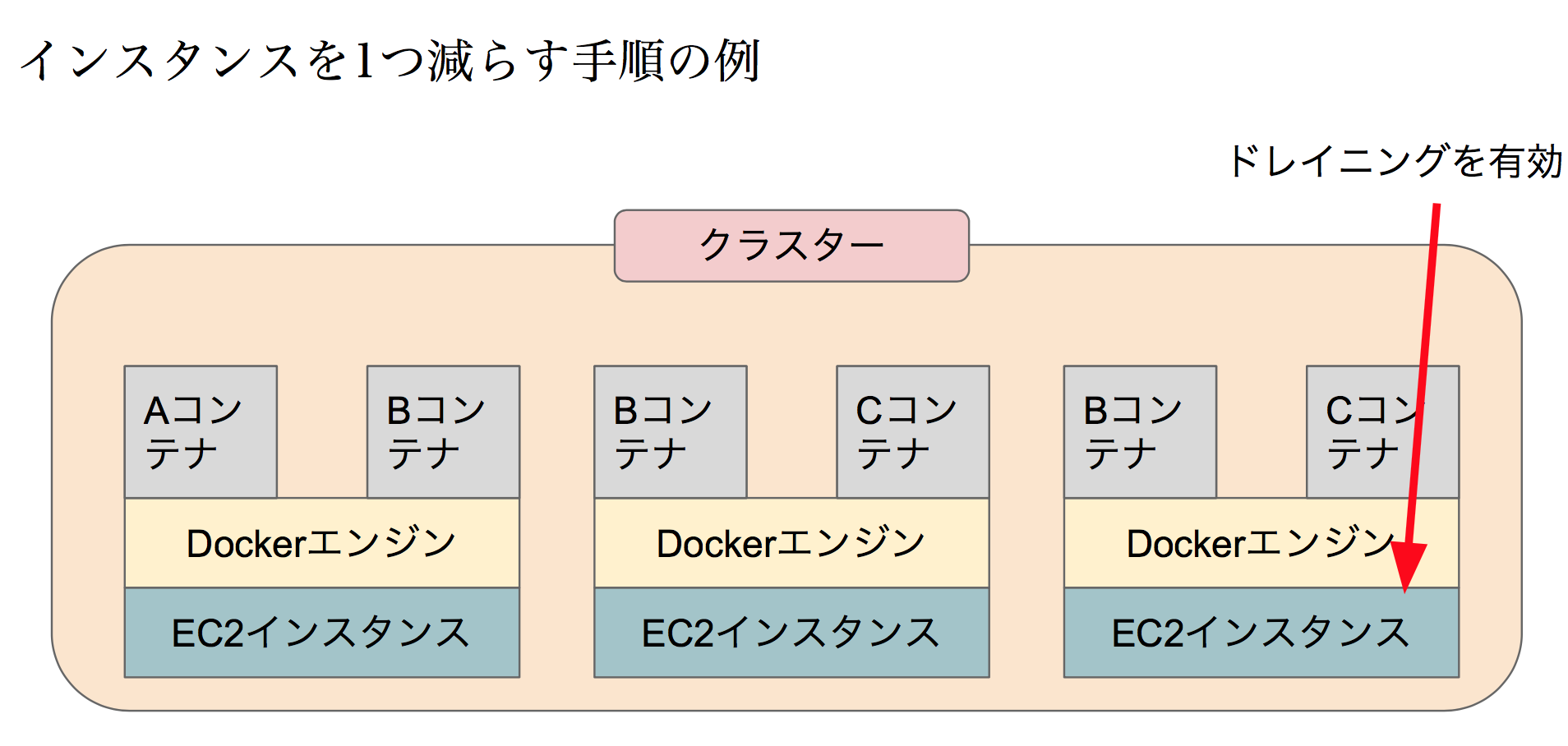
ECSのホストインスタンスのうち1台をドレイニング状態へ変更しました。
ドレイニング状態のインスタンスにはコンテナが立つことはできません。
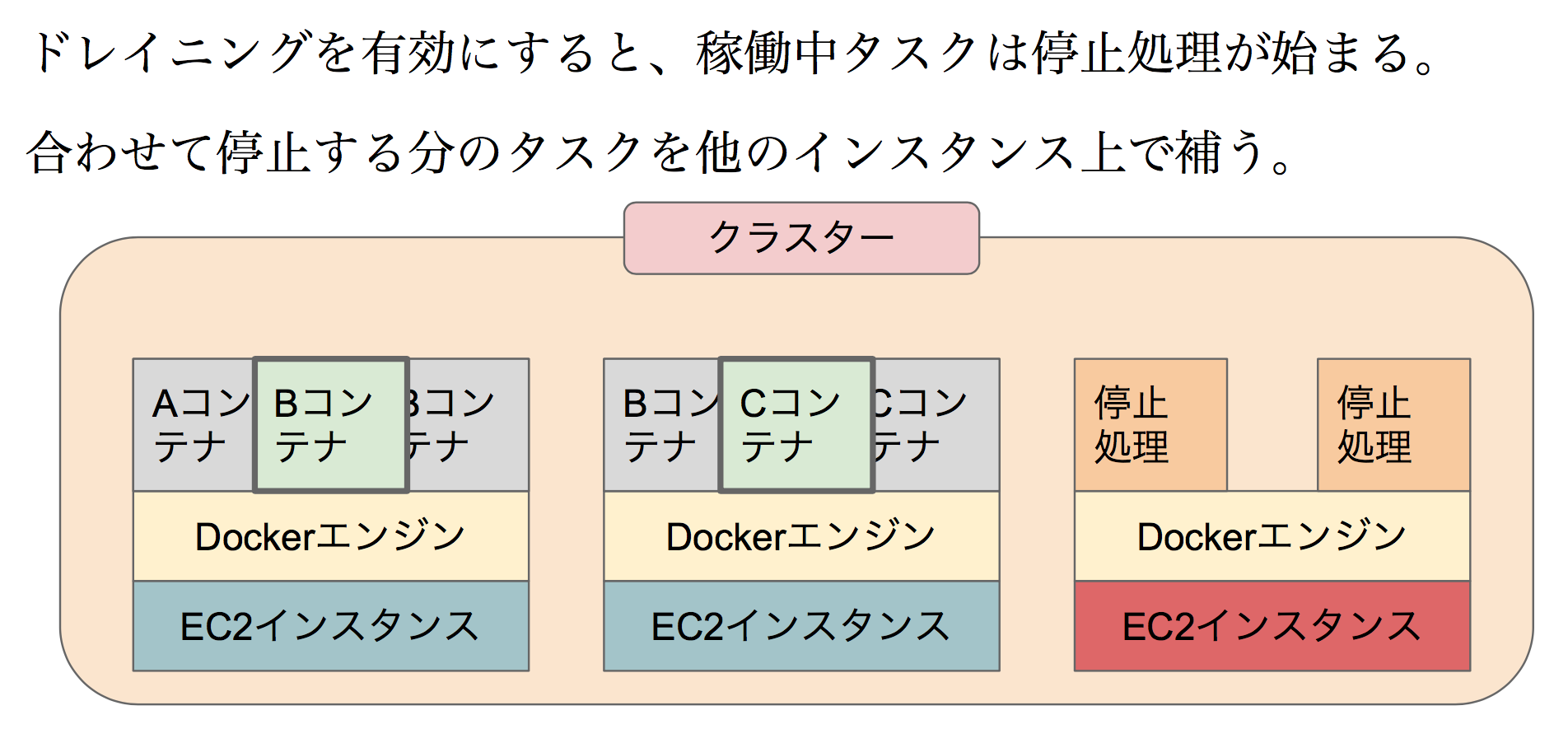
既に立っているコンテナについては、停止処理が実行されます。
そして停止する予定のコンテナの数だけ、別のホストインスタンス上に新たなコンテナが立てられます。
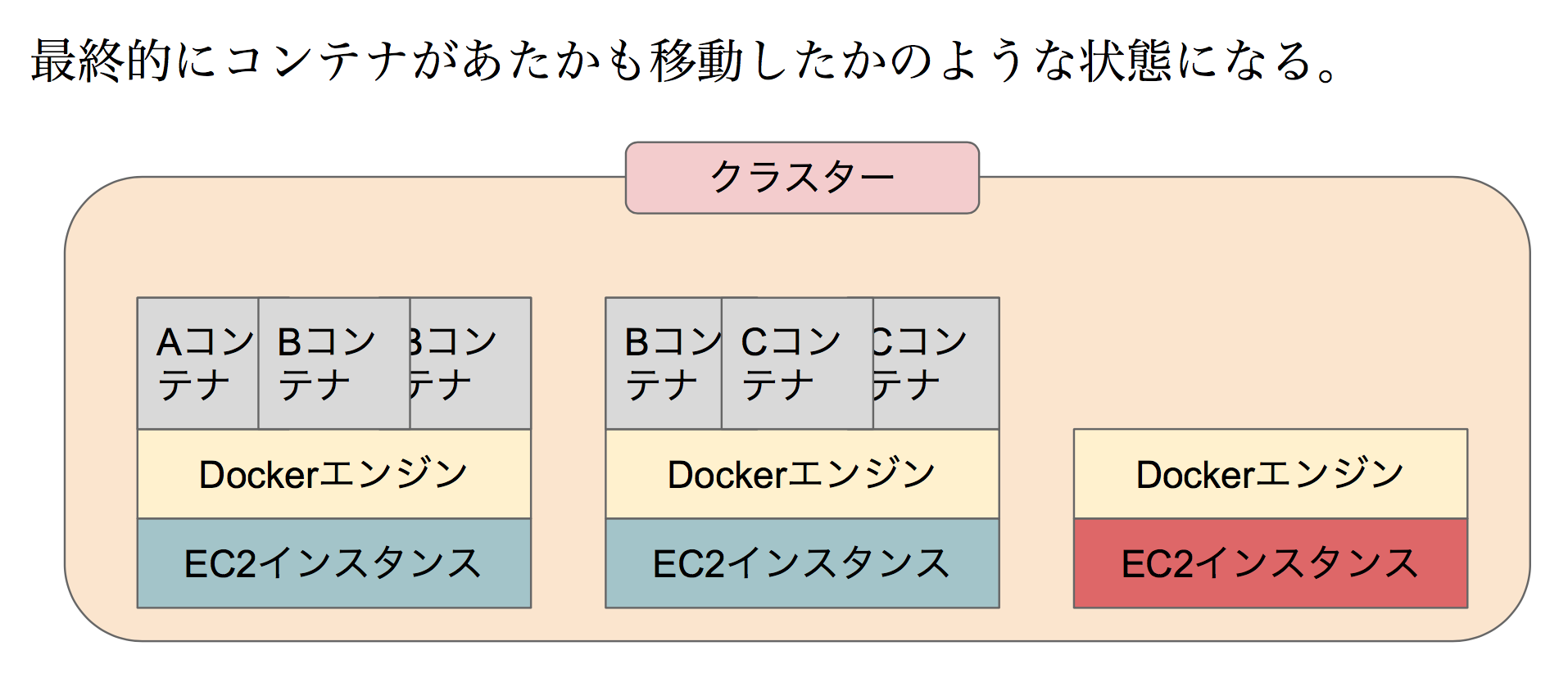
最終的にはあたかもコンテナが移動したかのような状態になりました。
これでドレイニング状態のインスタンスを停止すれば安全にインスタンスの数を減らすことができます。
ドレイニングの注意点
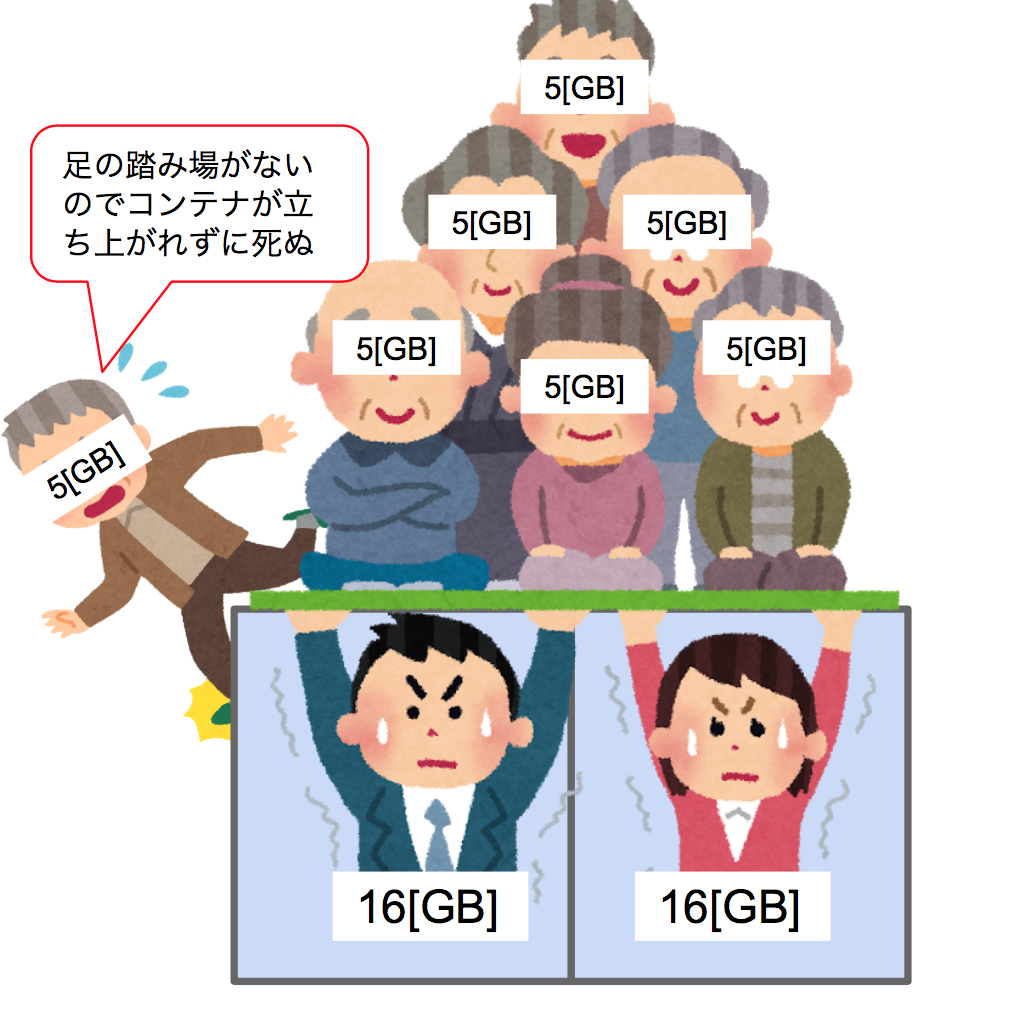
先ほどのケースでは問題にならなかったのですが、もしもアクティブ状態のインスタンスに新たなコンテナを立てるリソースがなかった場合にはどうなるのでしょうか。当然、新しいコンテナを立てることはできないのですが、ドレイニング状態のインスタンスにいつまでもコンテナを載せるわけには行かず、最終的に削除されてしまうか、延々とコンテナが残り続けてしまいます。
このケースによってサービス内のコンテナ数が0になってしまうとダウンタイムが発生する原因となりますので注意が必要です。
CPUリソースとメモリの両方について気をつけなければなりません。
個人的な意見となるのですが、タスク定義で割り当てるCPUリソースについては0を指定しておくとホストインスタンスのメモリのみを考慮すればよくなり管理が楽になります。(CPU消費の少ないサービスに限る)
もしくはサービスごとにコンテナが複数ある場合は最小ヘルス率を100未満にしておくことでも対策が可能です。
ドレイニングの導入
冒頭で記載したリンク(クリックで開く)に詳しい仕組みとGithubへのリンクが載っています。
しかしこのGithubで提供されているCloudFormationはサンプルのサブネットやECSまで作成してしまい、既に稼働済みのサービスに導入するためには不適切です。
そこで今回は必要最低限の機能のみのCloudFormationに作り直します。
AWSTemplateFormatVersion: '2010-09-09'
Description: >
AWS CloudFormation template to create a new Lambda function
This function supports automatic draining.
https://aws.amazon.com/jp/blogs/news/how-to-automate-container-instance-draining-in-amazon-ecs/
Parameters:
EcsClusterName:
Type: String
Description: >
Enter the target cluster name. ex) noname-test-cluster
Default: 'cluster'
EcsInstanceAsg:
Type: String
Description: >
Enter the AutoScalingGroup name.
Default: ''
Resources:
SNSLambdaRole:
Type: "AWS::IAM::Role"
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "autoscaling.amazonaws.com"
Action:
- "sts:AssumeRole"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AutoScalingNotificationAccessRole
Path: "/"
LambdaExecutionRole:
Type: "AWS::IAM::Role"
Properties:
Policies:
-
PolicyName: "lambda-inline"
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Action:
- autoscaling:CompleteLifecycleAction
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
- ecs:ListContainerInstances
- ecs:DescribeContainerInstances
- ecs:UpdateContainerInstancesState
- sns:Publish
Resource: "*"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "lambda.amazonaws.com"
Action:
- "sts:AssumeRole"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AutoScalingNotificationAccessRole
Path: "/"
ASGSNSTopic:
Type: "AWS::SNS::Topic"
Properties:
Subscription:
-
Endpoint:
Fn::GetAtt:
- "LambdaFunctionForASG"
- "Arn"
Protocol: "lambda"
DependsOn: "LambdaFunctionForASG"
LambdaFunctionForASG:
Type: "AWS::Lambda::Function"
Properties:
Description: Gracefully drain ECS tasks from EC2 instances before the instances are
terminated by autoscaling.
Handler: index.lambda_handler
Role: !GetAtt LambdaExecutionRole.Arn
Runtime: python3.6
MemorySize: 128
Timeout: 60
Code:
ZipFile: !Sub |
import json
import time
import boto3
CLUSTER = '${EcsClusterName}'
REGION = '${AWS::Region}'
ECS = boto3.client('ecs', region_name=REGION)
ASG = boto3.client('autoscaling', region_name=REGION)
SNS = boto3.client('sns', region_name=REGION)
def find_ecs_instance_info(instance_id):
paginator = ECS.get_paginator('list_container_instances')
for list_resp in paginator.paginate(cluster=CLUSTER):
arns = list_resp['containerInstanceArns']
desc_resp = ECS.describe_container_instances(cluster=CLUSTER,
containerInstances=arns)
for container_instance in desc_resp['containerInstances']:
if container_instance['ec2InstanceId'] != instance_id:
continue
print('Found instance: id=%s, arn=%s, status=%s, runningTasksCount=%s' %
(instance_id, container_instance['containerInstanceArn'],
container_instance['status'], container_instance['runningTasksCount']))
return (container_instance['containerInstanceArn'],
container_instance['status'], container_instance['runningTasksCount'])
return None, None, 0
def instance_has_running_tasks(instance_id):
(instance_arn, container_status, running_tasks) = find_ecs_instance_info(instance_id)
if instance_arn is None:
print('Could not find instance ID %s. Letting autoscaling kill the instance.' %
(instance_id))
return False
if container_status != 'DRAINING':
print('Setting container instance %s (%s) to DRAINING' %
(instance_id, instance_arn))
ECS.update_container_instances_state(cluster=CLUSTER,
containerInstances=[instance_arn],
status='DRAINING')
return running_tasks > 0
def lambda_handler(event, context):
msg = json.loads(event['Records'][0]['Sns']['Message'])
if 'LifecycleTransition' not in msg.keys() or \
msg['LifecycleTransition'].find('autoscaling:EC2_INSTANCE_TERMINATING') == -1:
print('Exiting since the lifecycle transition is not EC2_INSTANCE_TERMINATING.')
return
if instance_has_running_tasks(msg['EC2InstanceId']):
print('Tasks are still running on instance %s; posting msg to SNS topic %s' %
(msg['EC2InstanceId'], event['Records'][0]['Sns']['TopicArn']))
time.sleep(5)
sns_resp = SNS.publish(TopicArn=event['Records'][0]['Sns']['TopicArn'],
Message=json.dumps(msg),
Subject='Publishing SNS msg to invoke Lambda again.')
print('Posted msg %s to SNS topic.' % (sns_resp['MessageId']))
else:
print('No tasks are running on instance %s; setting lifecycle to complete' %
(msg['EC2InstanceId']))
ASG.complete_lifecycle_action(LifecycleHookName=msg['LifecycleHookName'],
AutoScalingGroupName=msg['AutoScalingGroupName'],
LifecycleActionResult='CONTINUE',
InstanceId=msg['EC2InstanceId'])
LambdaInvokePermission:
Type: "AWS::Lambda::Permission"
Properties:
FunctionName: !Ref LambdaFunctionForASG
Action: lambda:InvokeFunction
Principal: "sns.amazonaws.com"
SourceArn: !Ref ASGSNSTopic
LambdaSubscriptionToSNSTopic:
Type: AWS::SNS::Subscription
Properties:
Endpoint:
Fn::GetAtt:
- "LambdaFunctionForASG"
- "Arn"
Protocol: 'lambda'
TopicArn: !Ref ASGSNSTopic
ASGTerminateHook:
Type: "AWS::AutoScaling::LifecycleHook"
Properties:
AutoScalingGroupName: !Ref EcsInstanceAsg
DefaultResult: "ABANDON"
HeartbeatTimeout: "900"
LifecycleTransition: "autoscaling:EC2_INSTANCE_TERMINATING"
NotificationTargetARN: !Ref ASGSNSTopic
RoleARN:
Fn::GetAtt:
- "SNSLambdaRole"
- "Arn"
DependsOn: "ASGSNSTopic"
このCloudFormationを実行すると、実行に必要なIAMポリシーとドレイニングを実行するLambda関数、AutoScalingでの通知を受け取るためのSNSが生成されます。
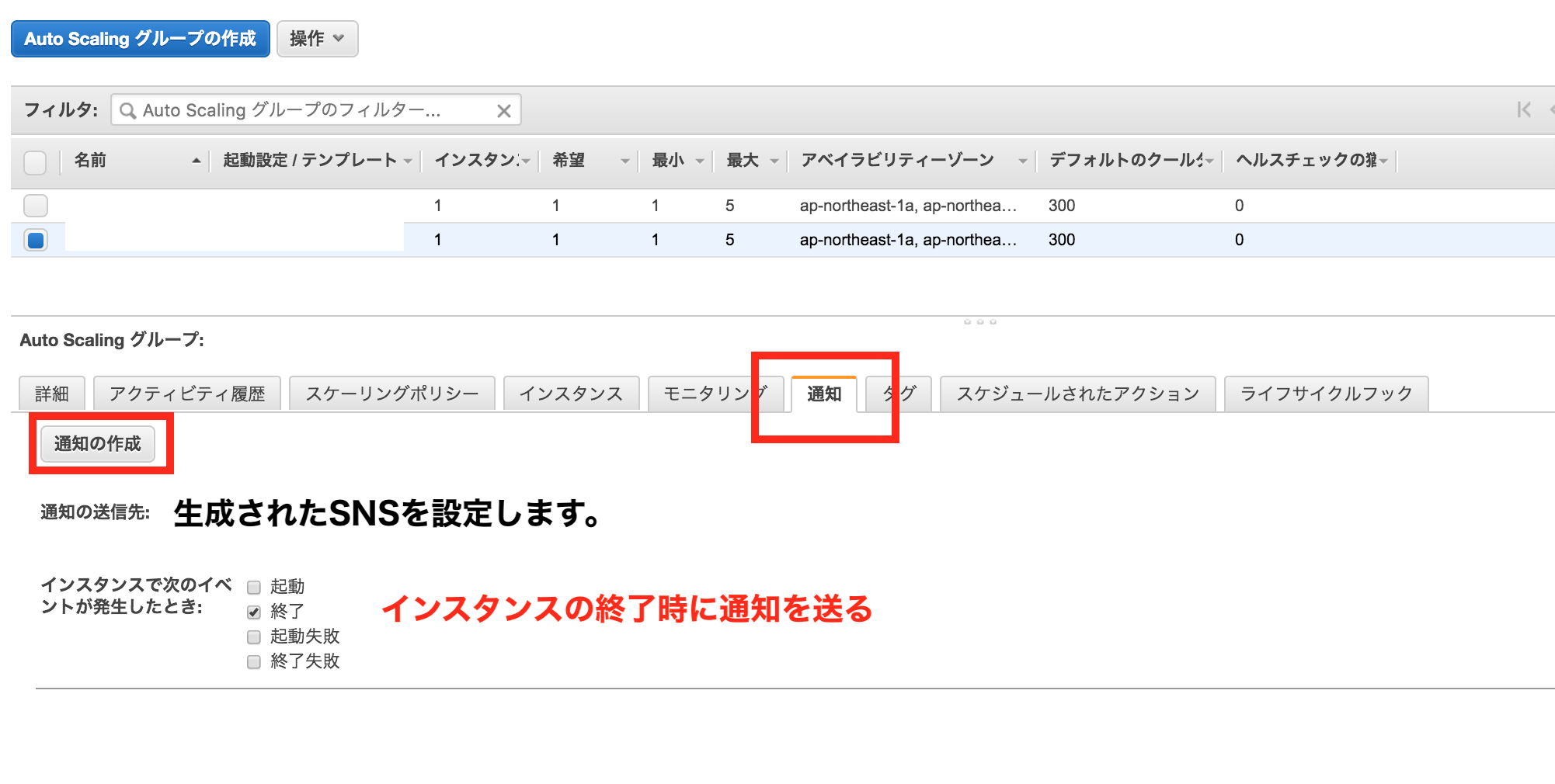
該当のAutoScalingグループの設定にて「通知」を作成して終了イベントを送信できるようにしてください。
これでAutoScalingによってインスタンスが終了する際にECSのホストインスタンスがドレイニングとなり、コンテナがなくなったことを確認のうえ停止されるようになります。
終わりに
自動でドレイニングが実行できるようになると、ECSのサービスを安全でスケーラブルな構成に組み替えることができます。
例えばServiceAutoScalingの設定で
・サービスのCPU使用率が一定値を超えたらコンテナを増やす
・サービスのCPU使用率が一定値を下回ったらコンテナを減らす
AutoScalingの設定で
・ECSクラスターの予約メモリのメトリクスが80%を超えたらインスタンスを増やす
・ECSクラスターの予約メモリのメトリクスが40%を下回ったらインスタンスを減らす
みたいな設定を入れ込んでおけば、突発的なユーザー流入や突発的な負荷でもない限りは適切なサイズに自動調整されます。
本来であればECSを使っている以上はこの構成にしておくのが望ましいのですが、もしもまだスケーラブルな構成になっていない場合には是非とも検討してみてください。スポットインスタンスとも相性が抜群です。
また、リザーブドインスタンスを購入していない場合にはFargateを使用するというのもありだと思いますよ!









コメントを残す