2019年12月にECSでのCluster AutoScalingが発表されました。
具体的にはキャパシティープロバイダーを使用することで、ECSタスク量に応じた適切なインスタンス数にスケールすることができるという機能です。
従来の方法ではCPUやメモリのの使用率や予約に応じてEC2インスタンスをスケールする方法が主でしたが、キャパシティプロバイダを使うことで計算に基づいた必要なインスタンス数を割り当てることができます。
それが本当だったらまさに夢のような機能ですね!
ということでさっそく環境を作成して検証してみました。
検証環境の作成
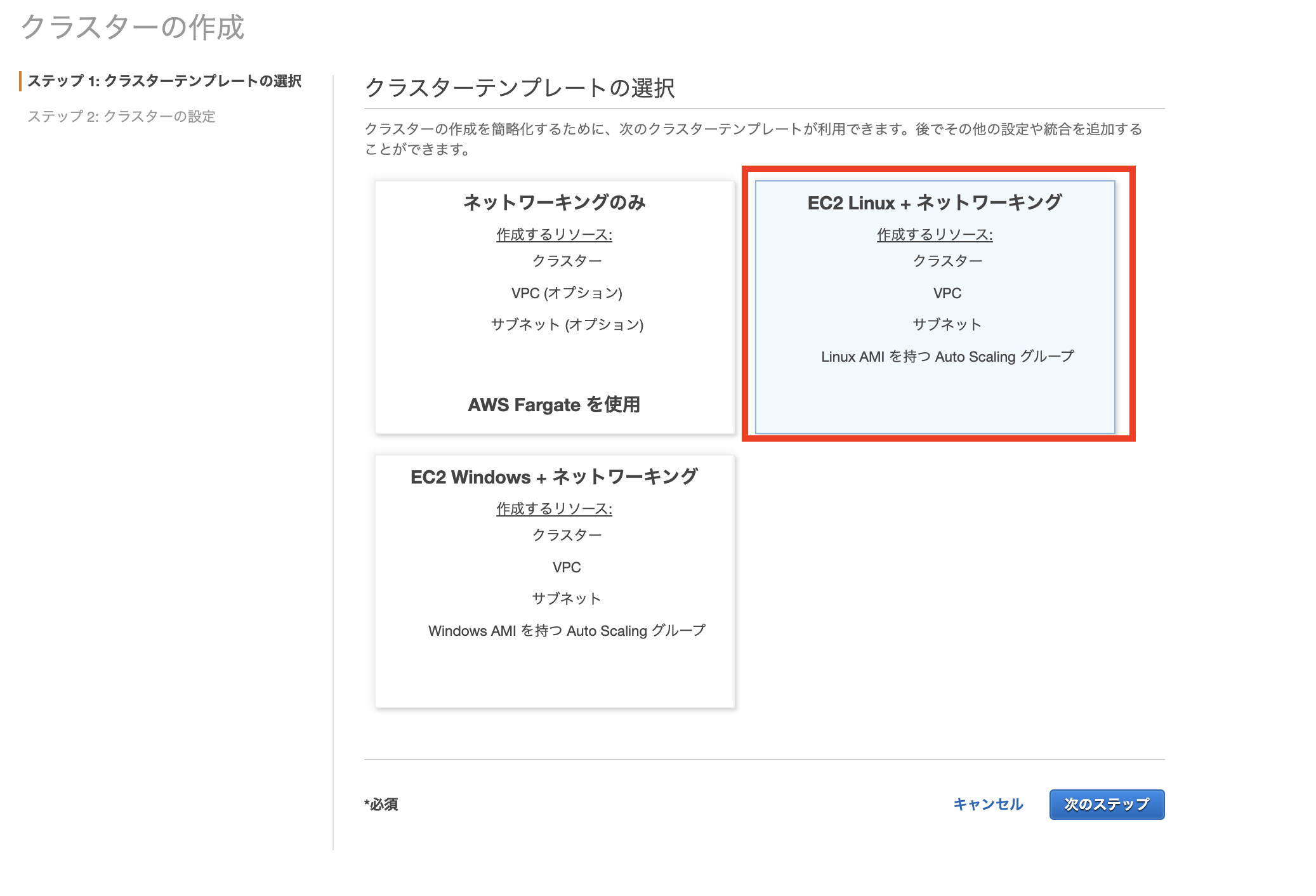
検証を行うためにEC2インスタンスをホストとしたECS環境を作成します。
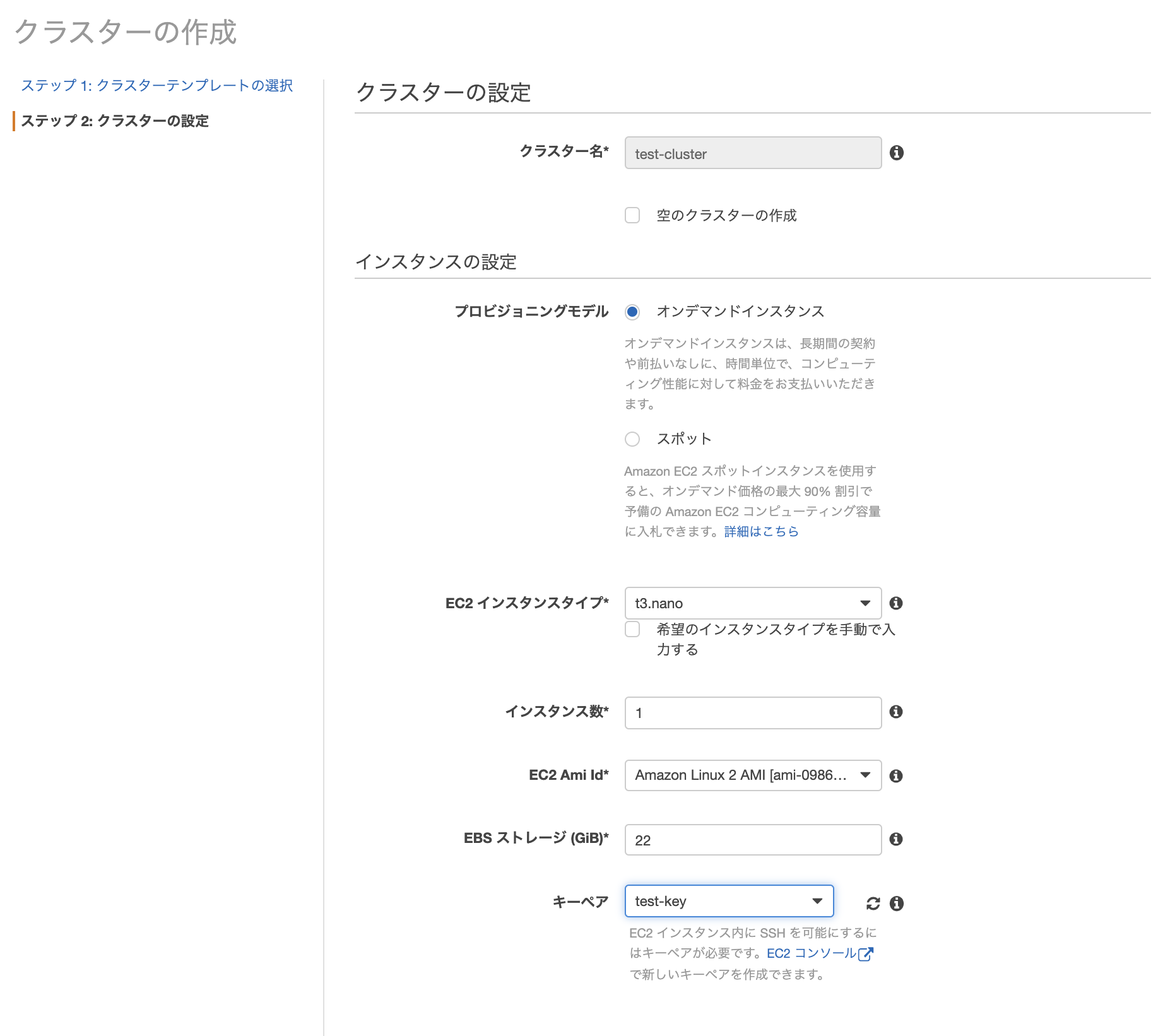
EC2のAutoScalingグループも作成しました。
本来ならコストカットのためにオンデマンドインスタンスとスポットインスタンスを両方使う構成をオススメしたいのですが、今回は短期間の検証になるためオンデマンドインスタンスをベースとした設定にしています。
これでクラスターの用意はできました。
タスク定義とサービスは検証のタイミングで作成します。
キャパシティープロバイダーの設定

ECSクラスターのコンソールに「キャパシティープロバイダー」のタブがありますのでここから作成を行います。

キャパシティプロバイダの設定項目で気をつけなければならないところは3箇所あります。
まずはマネージドスケーリングを有効にすることです。
これが有効になっていなければ、タスク数に応じた自動的なスケーリングは行われません。
次にターゲットキャパシティを1~100%の範囲で指定することです。
ターゲットキャパシティによってECSで使用するインスタンスの必要数が決まります。
(ターゲットキャパシティ / 100) = (インスタンスの必要数 / 現在のインスタンス数)
です。
すなわちターゲットキャパシティを50に設定すると、
50 / 100 = 必要数/現在数
現在数 = 2倍の必要数
よってターゲットキャパシティが50の時は、本来必要なインスタンスの数の2倍を構えることになります。
多めになリソースを構えることで突発的なターゲットの追加にすぐに対応できます。
また、ターゲットキャパシティを100に設定すると、全てのインスタンスが無駄なく使用されます。
最後にマネージドターミネーション保護の設定も重要です。
これはEC2のAutoScalingグループ内でスケールインから保護しなければならないインスタンスがある場合には有効にします。
逆に、保護すべきインスタンスがない場合は無効で問題ありません。

キャパシティプロバイダの設定ができたら、[クラスターの更新]から設定を有効にします。
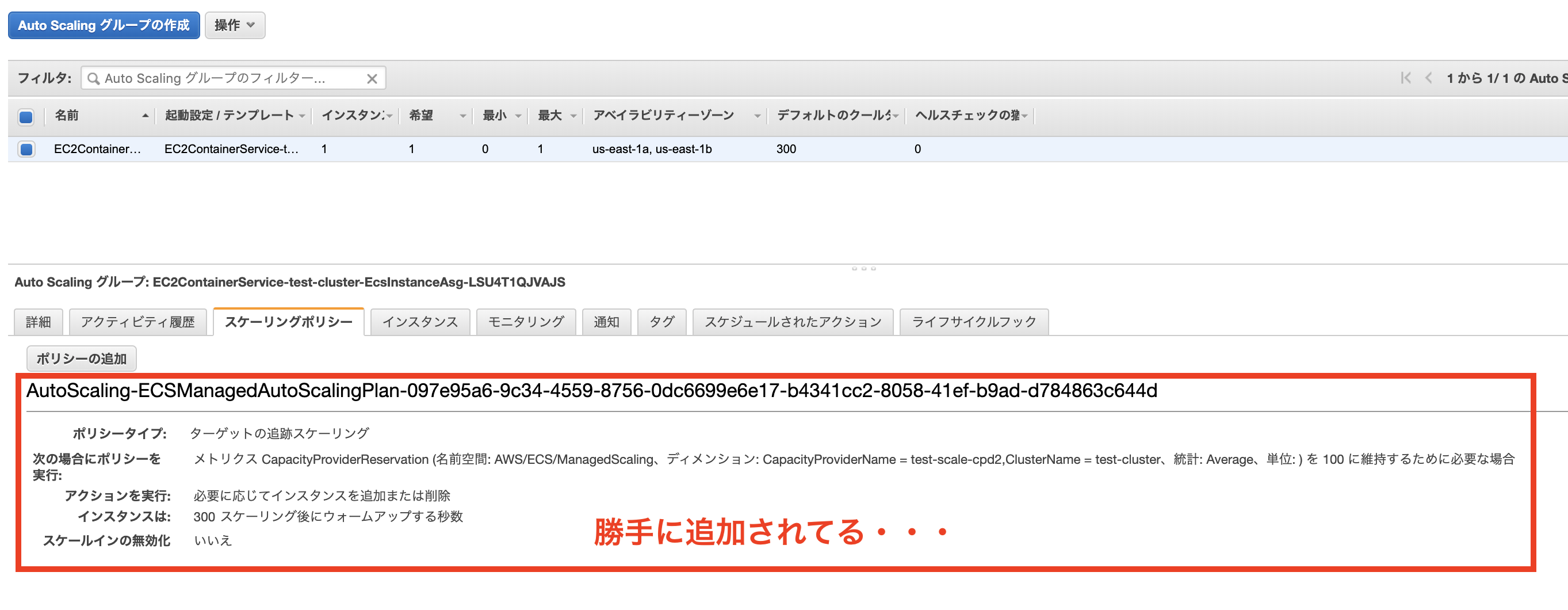
EC2のAutoScalingグループを確認すると、スケーリングポリシーが適用されていることがわかります。
この後の検証のためにAutoScalingの最小値を最大値を変更しておきましょう。
動作の確認
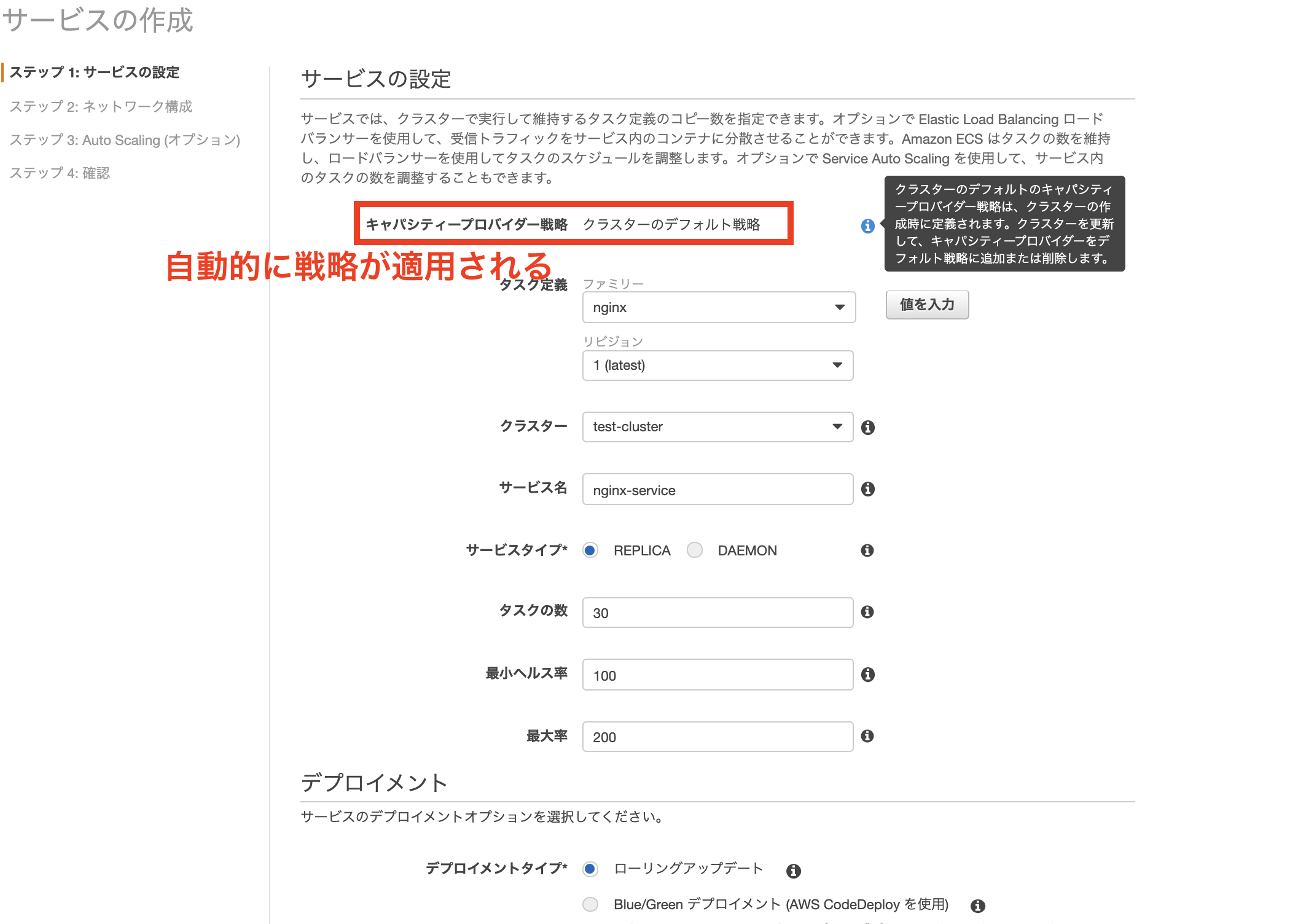
動作を確認するためにNginxを立ち上げるタスク定義を作成しておきました。
ECSからサービスを作成しようとすると、[キャパシティープロバイダー戦略]が適用されていることがわかります。
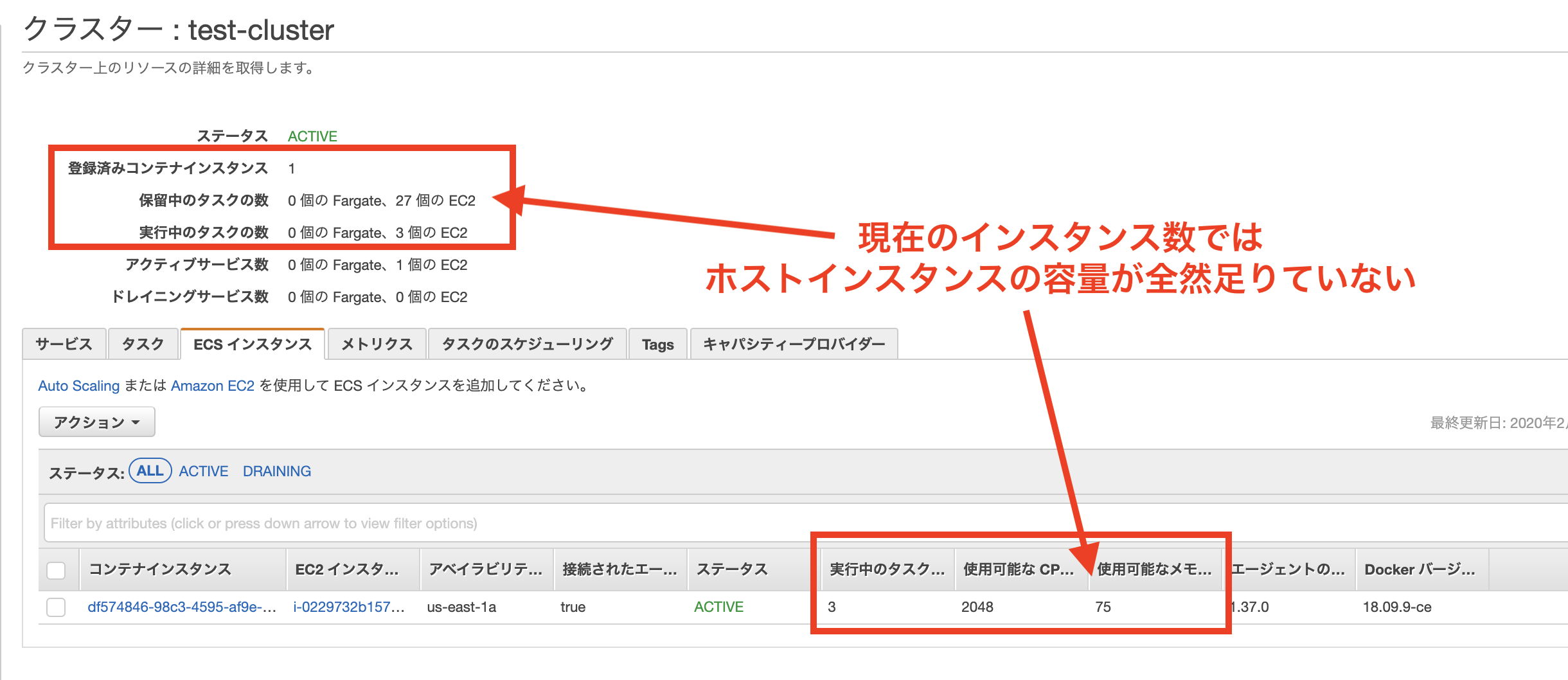
今回のケースではEC2インスタンスは1台しか立っていないのですが、1台あたり3つまでしかタスクを起動することができません。
残り27個のタスクを立ち上げるためにはEC2インスタンスが後9台必要ということになります。
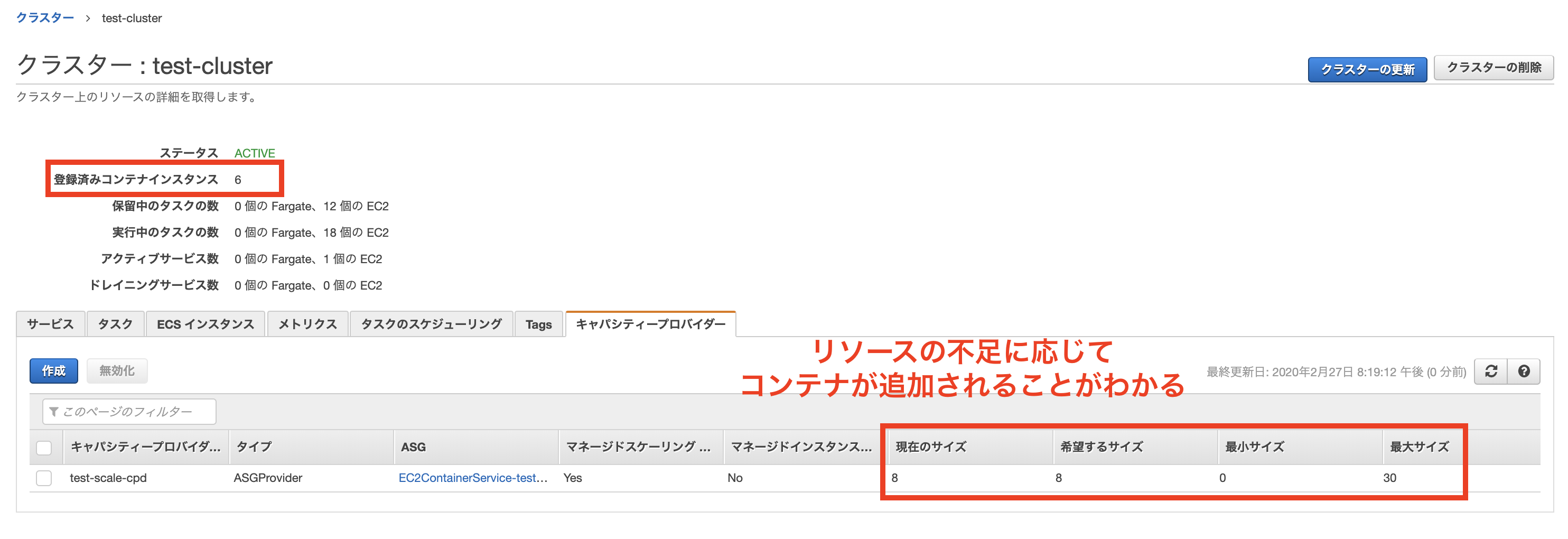
その状態のまま観察していると、キャパシティープロバイダーによって自動的にEC2インスタンスの数が増えていることが確認できます。
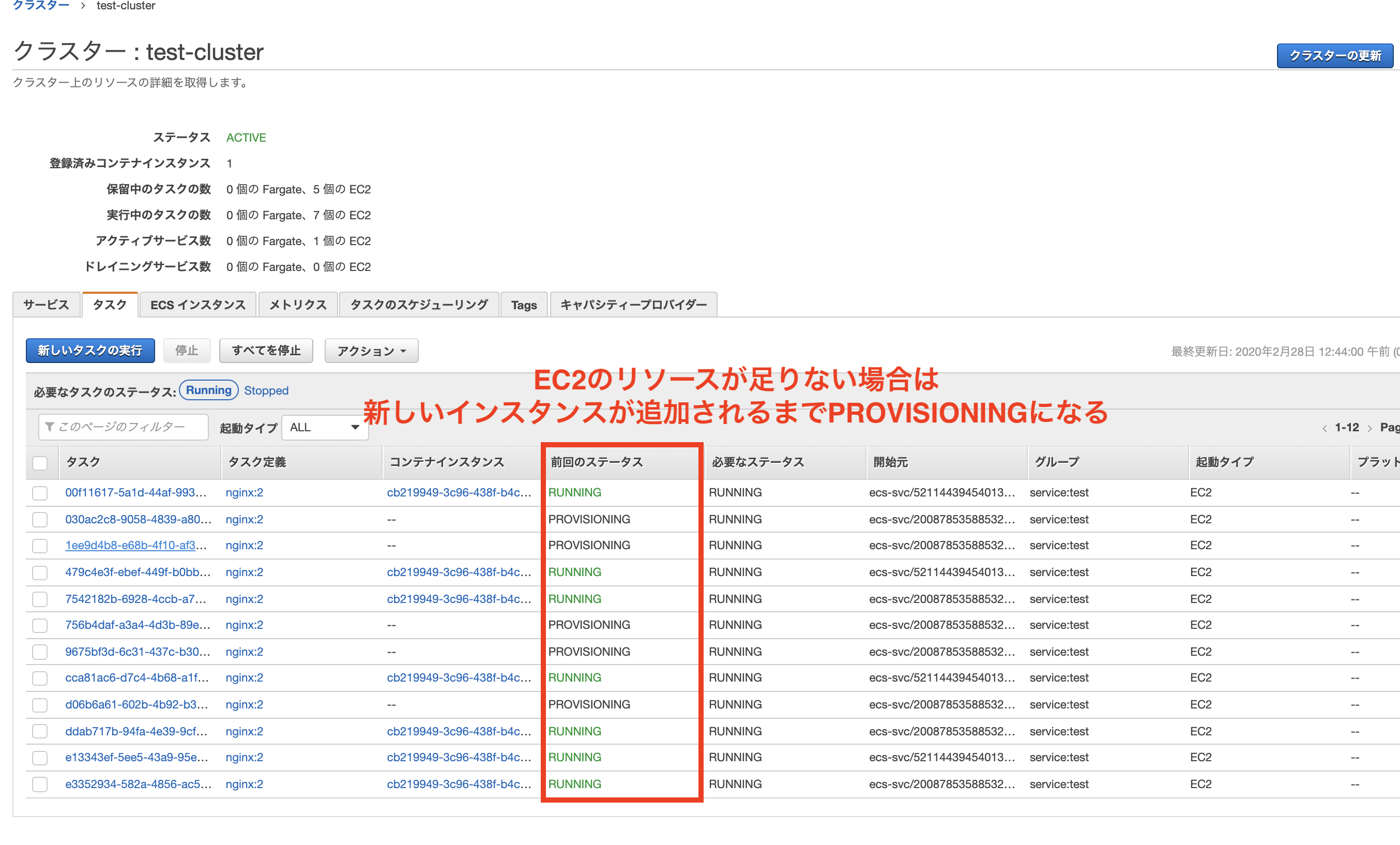
リソース不足で新たなタスクが起動できない場合は、本来であればコンテナはストップ状態になり立ち上がらないのですが、キャパシティープロバイダーの戦略が有効になっている場合には[PROVISIONING]という状態になりリソースが増えるまで待機してくれます。
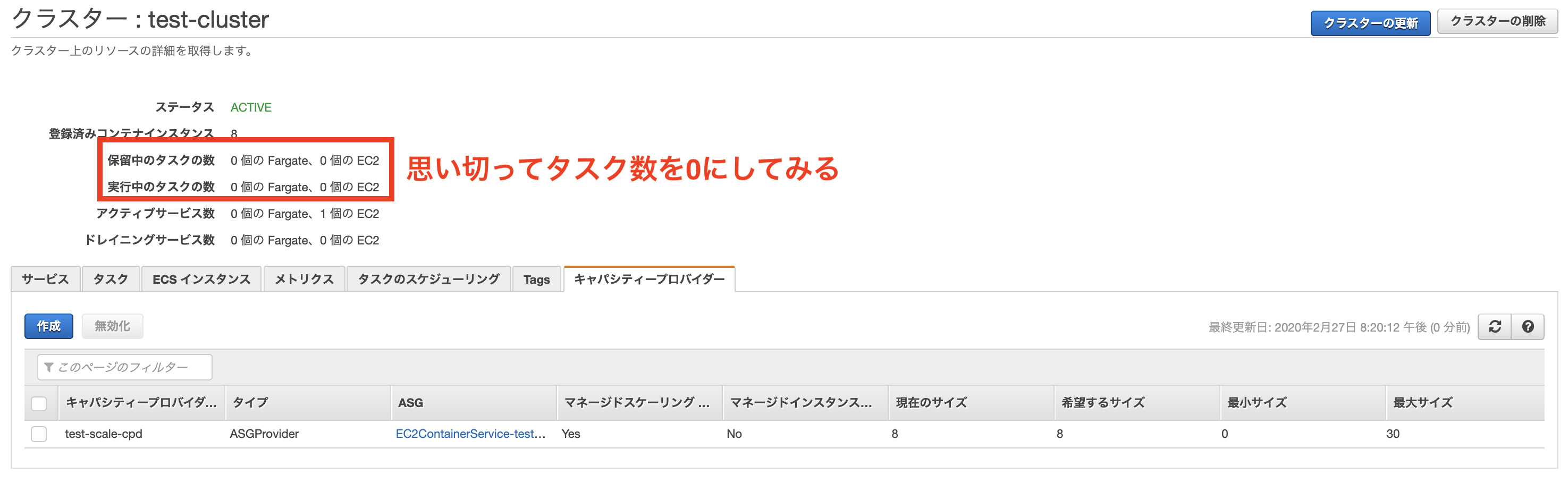
リソースが不足している時、自動的にインスタンス数が増えることは確認できました。
引き続きスケールインの動作を確認してみます。そこで思い切ってタスクの数を0にしてみました。
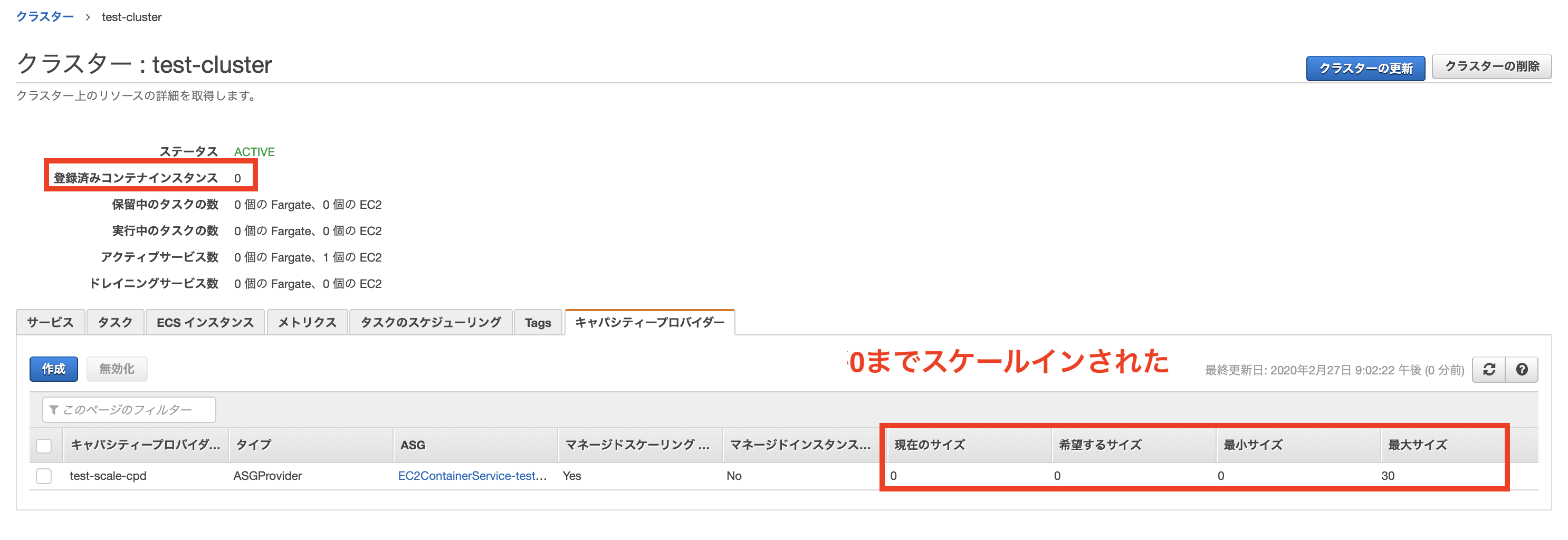
すると最終的にインスタンスの数が0までスケールインされることがわかりました。
サービスデプロイ時のスケールアウト戦略
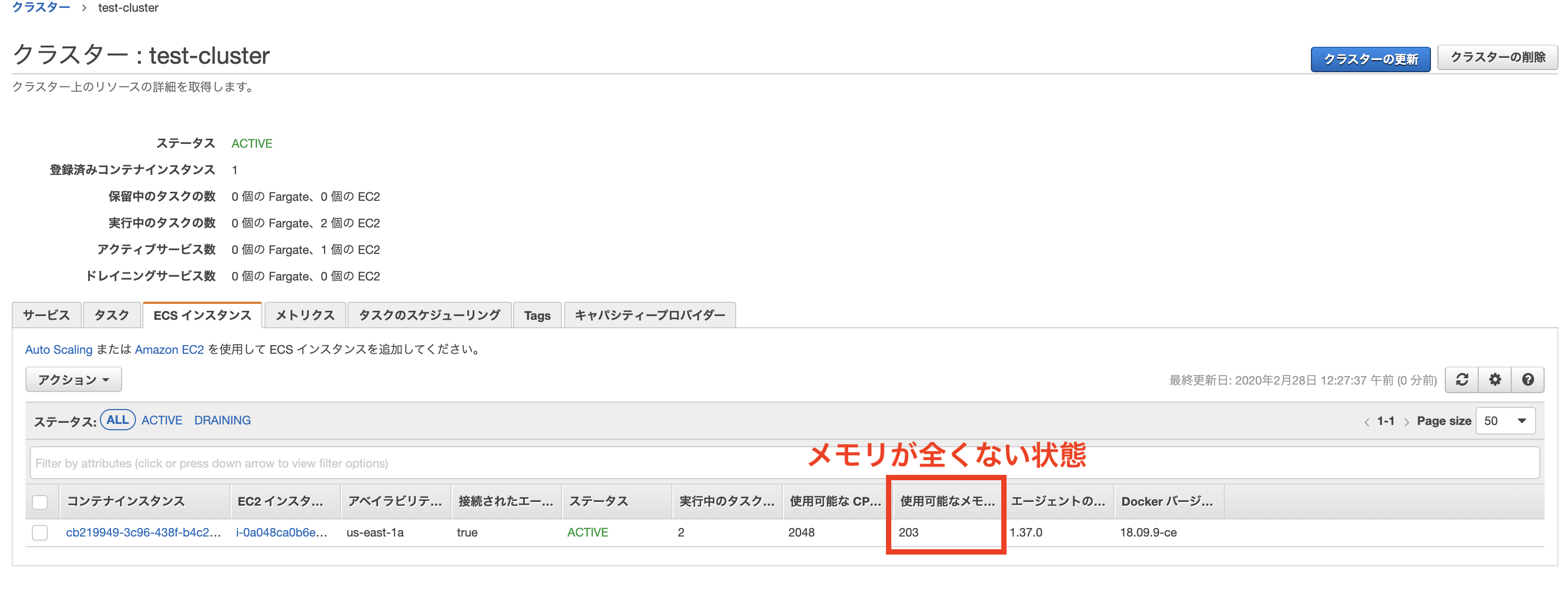
添付画像のようなケースを考えてみます。
1台のEC2インスタンスにはタスクが2つまで立ち上がることができます。
このタスクによってインスタンスのメモリが予約されており、これ以上は新たなタスクを立てることができません。
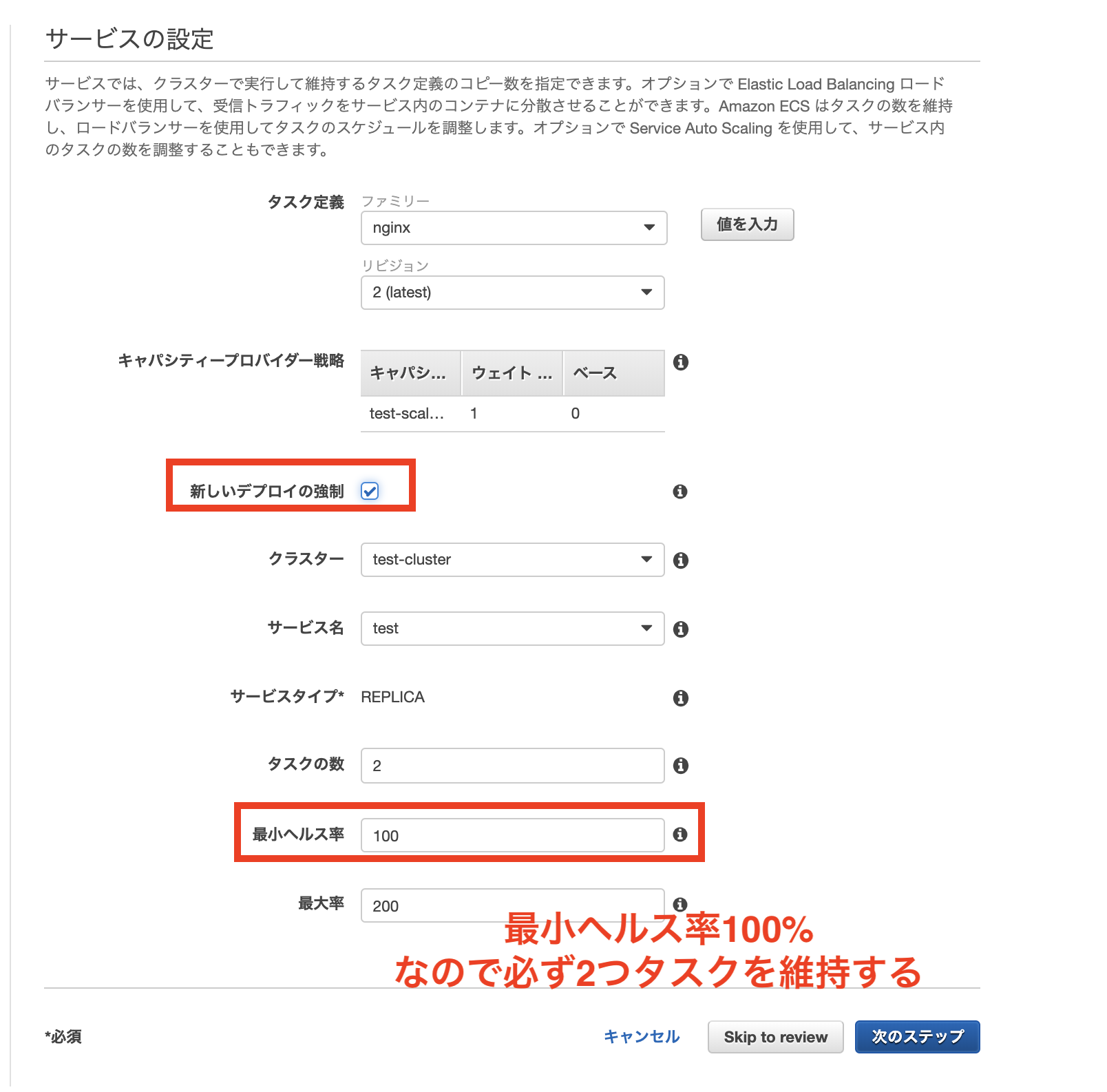
この時に[最小ヘルス率]を100%にして新しいサービスのデプロイを実施します。
ローリングアップデートなので、この場合には新しいタスクが立ち上がってから古いタスクが徐々に入れ替わるように削除される流れとなるのですが、そもそも新しいタスクを立てるためのリソースが不足しています。
このケースではキャパシティープロバイダーの戦略によって一時的にEC2インスタンスが追加されることを期待していたのですが、いつまで経っても追加されることはありませんでした。
↑改めて同じ状況下で確認したらきちんとEC2インスタンスが追加されました。
あくまでデプロイのためのリソース不足には対応していないのかもしれません。
(検証不足でしたらすいません><)
この辺りについては自分でスケーリングのポリシーを組んだ方が使い勝手は良さそうですね。
その他まとめ
・スケールされる範囲はAutoScalingグループの最小-最大の範囲のみ。
・スケールインが実行されるのはサービスで作られたタスクが存在しないインスタンスのみ。
・そのためバランスよくタスクが配置されるとなかなかインスタンスが消えない。
・キャパシティープロバイダー戦略と別に自分で作成したスケーリングポリシーも同時に設定できる。
・少なくともスケールインについては自分でルールを作った方がいいかもしれない。
・キャパシティープロバイダー戦略では[DEAMON]は無視される。
終わりに
キャパシティープロバイダー戦略を単体で使用するだけでは、デプロイ時のみリソースを増やしたり、クラスター全体のCPUやメモリが過剰な時にスケールインをするときに想定通りの挙動をしないかもしれません。
しかし、スケールアウトについては結構便利で、ServiceAutoScalingの設定だけでインスタンスのスケールアウトも管理できるようになります。
動作確認をした限りではタスクが存在しているインスタンスはいつまで立ってもスケールインされないので、リソースが過剰な時は自動的にドレイニングしてスケールインしてくれるようになるとなお良さそうですね。(ここは自分でスケーリングポリシーを書けば簡単に対応できますが・・)
この機能を今の実務で有効にするかの判断がまだできていませんが、少なくとも「設定をしておくと便利そう」くらいの印象は受けました。
個人の範囲ではユースケースが限られてしまいますが、実務の開発環境などに導入して経過を見て判断すると良いかもしれません。







コメントを残す