※追記事項
AuroraエンジンのアップグレードでMySQLプロセスが停止して復旧困難になるケースについて、原因の返答がありました。
RDSインスタンスにそれぞれ設定されている最大接続数の推奨値に近い接続があると発生しやすいようです。
これはインスタンスのサイズが大きくなるほど、発生する可能性は小さくなることが見込めますが、t2系などの小規模なものを使用している場合には接続数が少なくとも発生する恐れがあります。
◆AWS側が推奨しているデフォルトの接続数は下記をご覧ください。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Managing.Performance.html
————-
アップグレードのお知らせ
先日、AWSのメールに下記の文面のお知らせが来ていました。
内容はAurora MySQLのエンジンバージョンが2.07.2(1.22.2)未満の場合にはアップグレードが行われるというものです。
Aurora MySQL 2.07.2 (1.22.2) には複数の重要な修正、及び、累積的なセキュリティ修正が含まれており、4ヶ月以上安定した動作が確認されているため、できるだけ早く該当する Aurora MySQL インスタンスを Aurora MySQL 2.07.2 (1.22.2) にアップグレードすることをお勧めします。
2020 年 8 月 12 日以降、DB インスタンスにおいて、「マイナーバージョン自動アップグレード」が有効に設定されている場合、メンテナンスウィンドウ中に Aurora MySQL インスタンスが自動的に Aurora MySQL 2.07.2 (1.22.2) にアップグレードされます。アップグレードを自動適用したくない場合は、2020 年 8 月 11 日までに「マイナーバージョン自動アップグレード」を無効に設定してください。
データベースの使用できない期間は、ワークロード、クラスタサイズ、及び、ダウンタイムのないパッチ適用 (ZDP) 機能が正常に実行されるかどうかによって異なります。Aurora DB クラスターを更新するにはデータベースを再起動する必要があるため、DB クラスターの使用を再開できるまで、短期間ダウンタイムが発生することがあります。バイナリログ記録の量は、復旧時間に影響を与えます。バイナリログに記録されるデータの量が多い場合、DB インスタンスは復旧中にさらに多くのデータを処理する必要があるため、復旧時間が長くなります。
自動アップグレード機能を無効にしていれば勝手に実施されることはありませんが、脆弱性に対するセキュリティ修正が含まれているためなるべく実施したいところです。
さて、Auroraのアップグレードではダウンタイムのないパッチ適用が可能です。
しかし実際にダウンタイムが発生してしまうのか、ダウンタイムなしで適用できるのかの基準が不明なところが不安ですね。
今回は実際にAuroraアップグレードを実施して発生したパターンを紹介します。
ちなみにAuroraバージョンは2.03系からのアップデートです。
1,ダウンタイムなしで適用されたパターン

実行後に0ダウンタイムでのパッチ適用に成功した旨の説明が表示されています。
この文章が表示されている場合には、本当にダウンタイムが存在しないor数十秒だけダウンタイムが発生したケースが確認できました。
ただしパッチ適用中にはRDSのCPU使用率が跳ね上がり、レスポンスに遅延が生じていました。
2,DBインスタンスが再起動したパターン

「1,ダウンタイムなしで適用されたパターン」と同じエンジンバージョンだったのですが、パッチ適用の際にDBインスタンスが再起動したパターンもありました。
再起動自体は2分以内に完了しましたが、明確にダウンタイムが発生していることが確認できました。
私の確認した環境ではWriterインスタンスはダウンタイムなしでのパッチが適用されている場合でも、Readerインスタンスは再起動しているパターンも確認できました。
というかReaderインスタンスは必ず再起動していました。
3,クラスターがフリーズして長時間反応がなくなったパターン
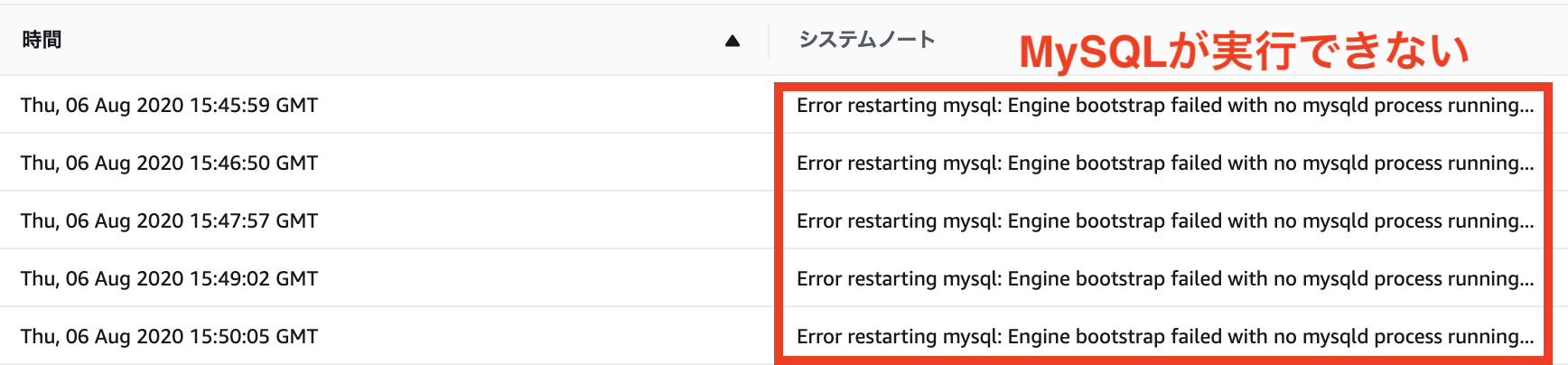
本当に原因が分からないんですが、Auroraのエンジンバージョンをアップグレードしたところ3時間以上もの間、アップグレードが終わらず、ログも取れず、接続もできず、メトリクスも表示されず、フェイルオーバーもできない状態になってしまいました。
この画像のログはやっとAuroraから返答が帰ってきた際に吐き出されたものです。
こうしてみるとMySQLのプロセスが正常に立ち上がっていないことがわかります。
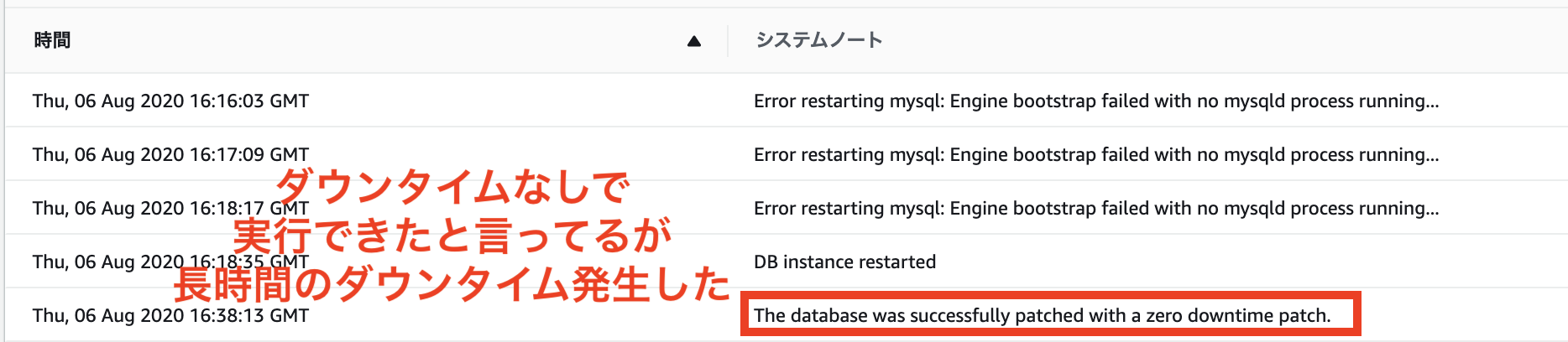
最後には「The database was successfully patched with a zero downtime patch.」なんて表示されてますが、がっつり4時間弱のダウンタイムが発生していました。
なぜこのような現象が発生したのかはAWSに確認してもらっていますが、個人的には下記のどれかが影響しているのかなと思っています。
・t2系の小さなDBインスタンスだった
・DB内のデータ量が非常に多いため
・バイナリーログの影響
ちなみにこのクラスターについては諦めて、「特定時点への復元」から新たなクラスターを複製してダウンタイムを最小限に抑えました。
終わりに
試した限りではダウンタイムのないパッチ適用(ZDP)機能はいまいち信用できないという印象です。
開発環境と本番環境でエンジンバージョンは同じでも本番環境に限ってダウンタイムが長めに発生したり、0ダウンタイムパッチが適用できたと言いつつダウンタイムが発生したり、と環境次第で影響範囲が変わっていました。
この感じではダウンタイムなしでのパッチ適用がうまくできればラッキー程度に思っておいて、メンテナンスを挟んだり深夜帯に実施したりときちんと対策をしておくべきでしょうね。
また、エンジンのアップデートが終わらない問題も発生したので、なるべく自動アップデートに頼るのではなく手動でアップデートを適用して問題が発生した場合には即座に対応できるように構えておくのが良いと思いました。
もう少し他の方のケースなども知っておきたいので、しばらくは様子見してからアップグレードの計画を練りたいですね。








コメントを残す